
Jupyter notebook(Python3)を使ってみようを使ってみようと思っても慣れていないうちは、どうしても処理に躓いてしまうものです。
例えば。Pythonのpandas機能にてソート(sort)をかけて昇順や降順で並び替え、データの上位10位を表示させる方法について理解していますか。
ここでは、このPandas(python)を用いてデータの上位の抽出する方法について解説していきます。
Pandasにて特定の列の数値を元に昇順(ソートする)に並び替えを行う方法【上位の抽出(python)】
まずはpandasにてデータの数値を昇順、降順に並び替え、上位10を抽出していく方法を確認していきます。以下のデータを活用していきます。

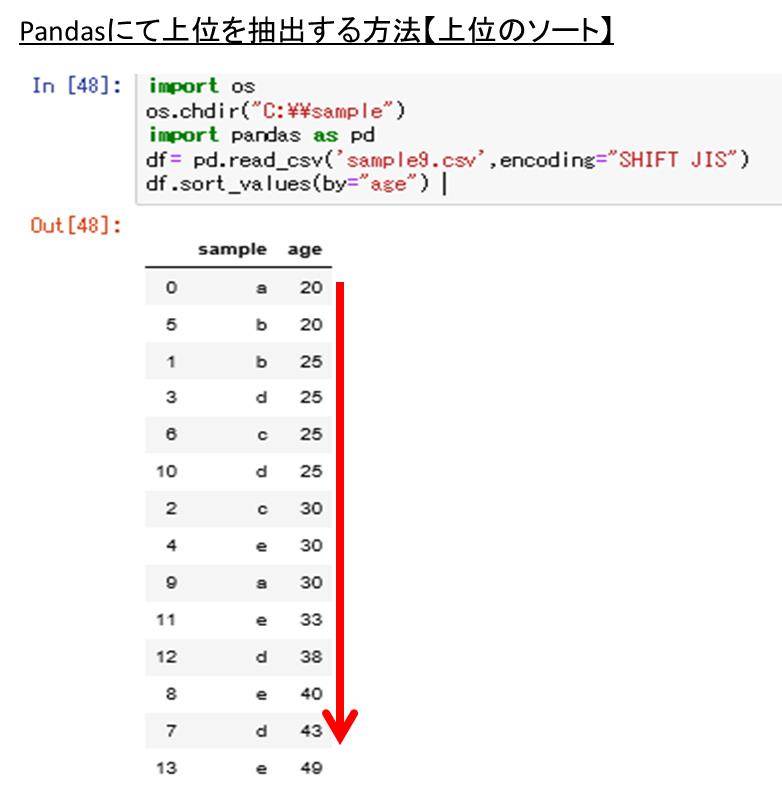
ここでageの列に着目して、数値の昇順への並び替えを行っていきます。このときpythonのsort_valuesの機能を活用するとよく、サンプルコードは以下の通りです。
os.chdir(“C:\\sample”)
import pandas as pd
df= pd.read_csv(‘sample9.csv’,encoding=”SHIFT JIS”)
df.sort_values(by=”age”)
ここでは、ageの列を昇順に並び変えてみました。
さらに、表示されたデータにおいて上位10位を抽出する際には、pandasのhead関数を使っていきます。
以下のよう()内に数値をいれるだけでいいです。

Pandasにて特定の列の記号を元に降順(ソートする)に並び替えを行う方法【上位の抽出(python)】
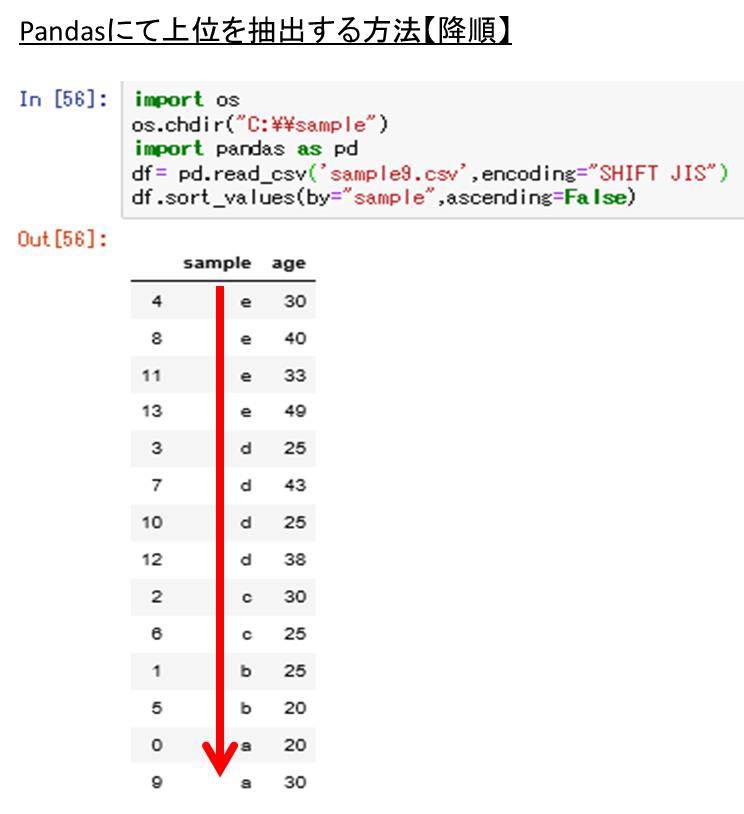
今度は、数値ではなく記号を元に降順に並び替えを行っていきましょう。以下のコードでは、sample列において、降順(ascending=False)に変化させることができます。
os.chdir(“C:\\sample”)
import pandas as pd
df= pd.read_csv(‘sample9.csv’,encoding=”SHIFT JIS”)
df.sort_values(by=”sample”,ascending=False)
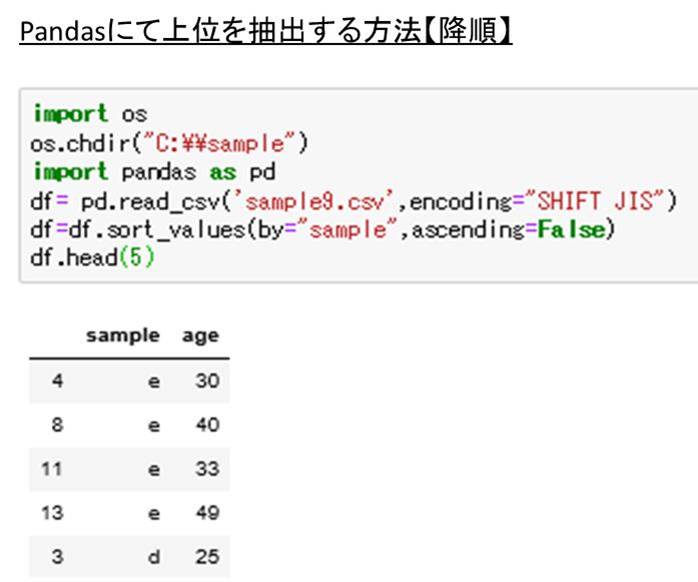
さらにここから上位5位を表示させてみましょう。上述の通りpandasにおけるhead関数を利用していきます。
os.chdir(“C:\\sample”)
import pandas as pd
df= pd.read_csv(‘sample9.csv’,encoding=”SHIFT JIS”)
df=df.sort_values(by=”sample”,ascending=False)
df.head(5)
これがpythonにおけるsample列を降順に並び替えた上で、上位5位を抽出する方法といえます。
pythonにて複数列の昇順と降順の並び替えを行う方法【上位の抽出(pandas)】
また、pandasにて特定の1列のみでなく、複数列に対する並び替えを行うことも可能です。
os.chdir(“C:\\sample”)
import pandas as pd
df= pd.read_csv(‘sample9.csv’,encoding=”SHIFT JIS”)
df.sort_values(by=[“sample”,”age”],ascending=[True,False])
このコードでは、sample列にて昇順で並べ、その次にage列では降順に並べていくような処理をしています。

このように、複数列でも昇順、降順の設定が可能なことを理解しておくといいです。
まとめ Pandas(python)にてソートを行い、上位を抽出させる方法
ここでは、jupyternotebook(python3)のpandas機能によって、昇順や降順にソートさせ、かつ上位を表示させる方法について解説しました。
基本的には、sort_values関数や条件を指定した上で、acssendingの対応を考えるといいです。
各種対処方法を理解して、pandasの使い方をマスターしていきましょう。

コメント