Jupyter notebook(Python3)を使ってみようと思っても慣れていないうちは、どうしても処理に躓いてしまうものです。
例えば、Pythonのpandas機能にて欠損値(NaN)にて欠損値のカウントや判定を行うにはどう処理すればいいのか理解していますか。
ここでは、このPython(Pandas)にて欠損値のカウント・判定を行う方法について解説していきます。
Python(Pandas)にて欠損値の判定を行う方法【insull関数】
それでは以下のサンプルデータを用いてPython(Pandas)にて欠損値:NaNかどうかの判定を行う方法について確認していきます。
元のcsvを読み込み、python上で出力させます。すると以下のよう欠損値の部分がNaNと表示されました。
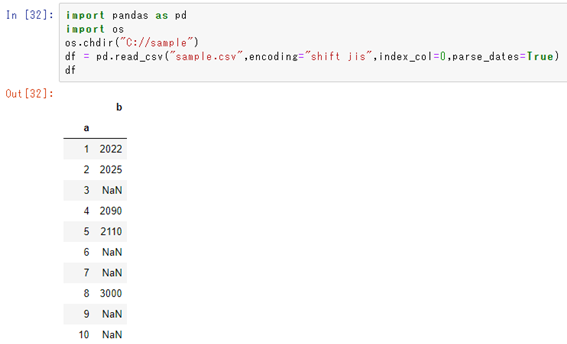
もちろんこれだけでも欠損値かどうかは判定できるものの、その後の欠損値の個数のカウントにつなげるよう変換するといいです。
具体的には欠損値(NaN)ならばTrue、そうでなければFalseと変換すべく、isnull関数を使用しましょう。
と入力・実行するだけでよく、以下のように出力されました。
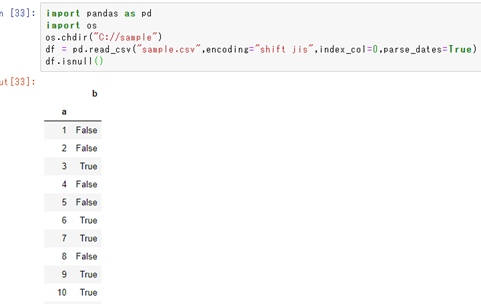
念のため、欠損値判定に必要となった一連の流れのコードの意味を記載していきます。
import os
os.chdir(“C://sample”)
df = pd.read_csv(“sample.csv”,encoding=”shift jis”,index_col=0,parse_dates=True)
df.isnull()
import pandas as pd
→pandasライブラリのインポート
import os
os.chdir(“C://sample”)
→osライブラリのインポート、csvが格納されているディレクトリへ移動
df = pd.read_csv(“sample.csv”,encoding=”shift jis”,index_col=0,parse_dates=True)
→csvを読み込みし、最左をインデックス列に(再度のparse_dates=Trueは日付データに変換したい場合に必要)
df.isnull()
→欠損値の判定
という具合です。
特定列のみの欠損値の判定を行う方法
上では全列に対する欠損値(NaN)の判定ができますが、列を指定して欠損値かどうかを判定することも可能です。
と単純に、指定したい列のみに絞ってから、isnullの処理をすればいいわけです。
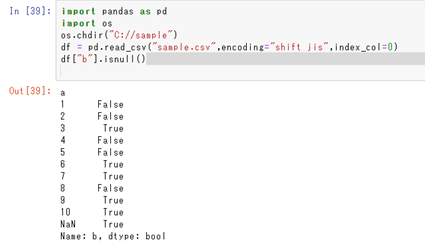
今回は元が1列のみ(インデックスを除き)だったため、ほぼ同じ形となっていますが、列数がおい場合に重宝されます。
欠損値の個数をカウントする方法
今度は上を用いて欠損値をカウントする方法についても確認していきます。
基本的には、上のisnullに加えてsum関数も組み合わせて処理するといいです。
入れるだけでいいです。
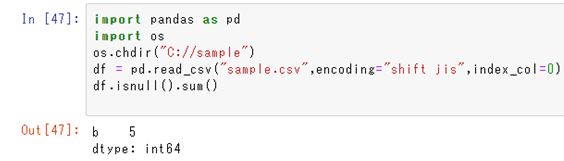
特定列のみの欠損値の個数をカウントしたいのであれば、df[“b”].isnull().sum()などど最初に列名を指定するといいです。
行方向の欠損値の個数を数える方法
なお列方向ではなく、行方向にてNaNのカウントを実行したいこともあるでしょう。
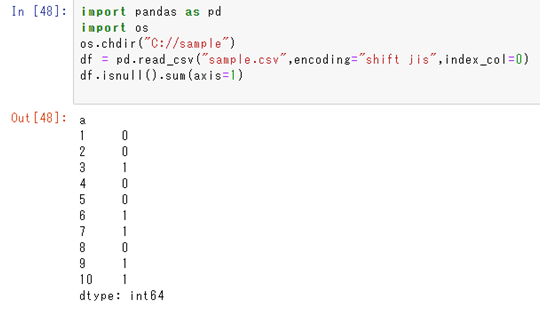
このような場合では引く数にてaxis=1と指定していくといきましょう。
この処理だけで、行方向での欠損値の個数をk添えることができましあ。
まとめ Python(Pandas)にて欠損値の判定・カウントはを行う方法【isnull】
ここでは、Python(Pandas)にて欠損値の判定・カウントを行う方法(isnull関数)について解説しました。
基本的には
・NaNの判定にはdf.isnul()
・NaNのカウントにdf.isnul(),sum()
と処理するといいです。
Pandas(Python)での各種処理方法に慣れ、より効率的なデータ解析を行っていきましょう。

コメント