
Jupyternotebookにてpythonを使いこなすためにには、さまざまな処理方法を理解しておく必要があります。
たとえば、Excelやcsvデータをpandasにてデータフレーム(dataframe)に読み込む際に、数値しか記載されていないデータの場合、ヘッダー行の追加(取得)や変更をしたいことがありますよね。このようなケースではどう対処するといいのか理解していますか。
ここでは、pandasにてcsvやexcelを読み込む際にヘッダー行の追加や変更を行う方法について確認していきます。
Pandasでヘッダー(ヘッダー行)を追加(取得)する方法【csvの読み込み時(read_csv時に最初の列を加える)、heder=Noneを活用する】
まず以下のようなcsvデータ(データ名:sample7)があるとします。
これをそのまま読み込もうとすると、以下のように最上行のデータ自体もヘッダーと認識されてしまいます。
import os
os.chdir(“C:\\sample”) #最初の2行はカレントディレクトリの移動のため
import pandas as pd
df = pd.read_csv(“sample7.csv”, encoding=”SHIFT_JIS”)
df

そのため、ヘッダー行を追加するコードを入力する必要がでてきます。具体的には、read_csv()の()内に、header=Noneというコードを追加するといいです。
import os
os.chdir(“C:\\sample”) #最初の2行はカレントディレクトリの移動のため
import pandas as pd
df = pd.read_csv(“sample7.csv”, header=None, encoding=”SHIFT_JIS”)
df
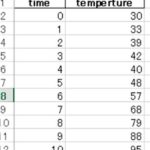
すると、以下のようにpandasにてcsvデータにヘッダーが追加された形で、データフレームに読み込みできました。

なお、上述ではcsvから読み込んでいく方法を確認しましたが、excelの際は、read_excel関数を使っていけばいいです。
Pandasでヘッダーを変更する方法【ヘッダー名の指定:csvやexcel読み込み時(read_csv時に最初の列を変える)】
header=Noneのコードでは、ヘッダーを追加する際に上のよう自動で0,1と番号が振られていきます(つまりはヘッダーの変更)。
ここで、ヘッダー名を指定したいのであれば、
import os
os.chdir(“C:\\sample”)
import pandas as pd
df = pd.read_csv(“sample7.csv”, names=[“age”,”height”], encoding=”SHIFT_JIS”)
df
とnames=のコードをcsv読み込み時に入れるといいのです。

なお、こちらも同様にcsvファイルでデータではなく、excelであっても同じように処理すればいいです。
まとめ Pandasにてヘッダーの追加(取得)や変更を行う方法(csvやexcel読み込み時)【Jupyternotebook(pyton)】
Pandasにてヘッダーラベルの追加や変更を行う方法(csvやexcel読み込み時)について確認しました。
Csvやexcelを読み込む際に、heade=noneもしくはnamesでのヘッダー名を変更するコードを入れていけばいいです。
Jupyternotebookでの操作に慣れ、より効率よい操作を目指していきましょう。
コメント