
Pythonを用いてデータ加工を行う際にはpandasライブラリを使用する機会が多いですよね。
このpandasを使い慣れていないと上手く処理できないことがあり、例えば時間の差分を計算したい場合にどのように処理すればいいのかわからないことはないでしょうか。
ここでは、このPython(Pandas)にて時間の差分を計算する方法について解説していきます。
Pandasにて時間の差分(diff)を計算する方法【Python】
それでは、Python(Pandas)にて時間の差を計算する方法について確認していきます。
まずは以下のような時間の列を含むexcelファイルを読み込むとします。
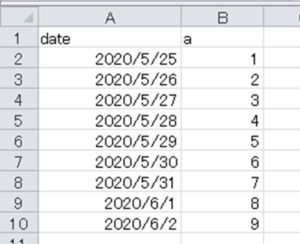
このexcelファイルを読み込み、pandasにて時間の差分を計算していくには以下のようなサンプルコードを記載していくといいです。
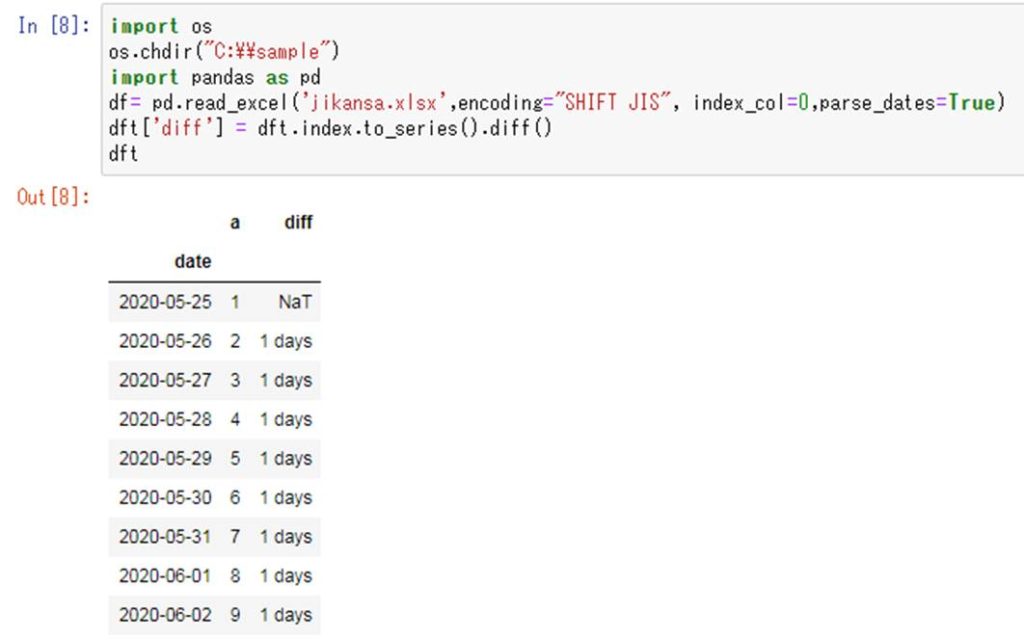
import os
os.chdir(“C:\\sample”)
import pandas as pd
df= pd.read_excel(‘jikansa.xlsx’,encoding=”SHIFT JIS”, index_col=0,parse_dates=True)
dft = df.set_index([df.index])
dft.index.names = [‘date’]
dft[‘diff’] = dft.index.to_series().diff()
dft
コードの意味について具体的に解説していきます。
import os
os.chdir(“C:\\sample”)
こちらにてexcelファイルが置いてある場所にカレントディレクトリを移動させます。
import pandas as pd
df= pd.read_excel(‘jikansa.xlsx’,encoding=”SHIFT JIS”, index_col=0,parse_dates=True)
こちらにてpythonのpandasライブラリをインポートし、jikansaという名前のエクセルファイルの読み込みをします。この際、A列(0番目のカラム)に相当する時間の列をインデックス列として、さらに「parse_dates=True」で時系列データとして扱っていきます。
dft = df.set_index([df.index])
dft.index.names = [‘date’]
さらにインデックスの列の名前をdateとしています。この列名変更はしなくてもいいです(今回は英語での表記にしてみました)
dft[‘diff’] = dft.index.to_series().diff()
こちらのdiff()によって差分を計算しています。なお、インデックスに対応する時間のデータをto_series().によって差分を取れる数値として処理していることがポイントといえますね。
これで、インデックスではない列として時間の差分を計算できています。なお、このdiffは「対応行の次の行の数値」ー「対応行の数値」で差分をとっていくものです。
ちなみにdiff()の中身はデフォルトで1であり、-1とすると「対応行の数値」ー「対応行の一つ前の行の数値」となります。
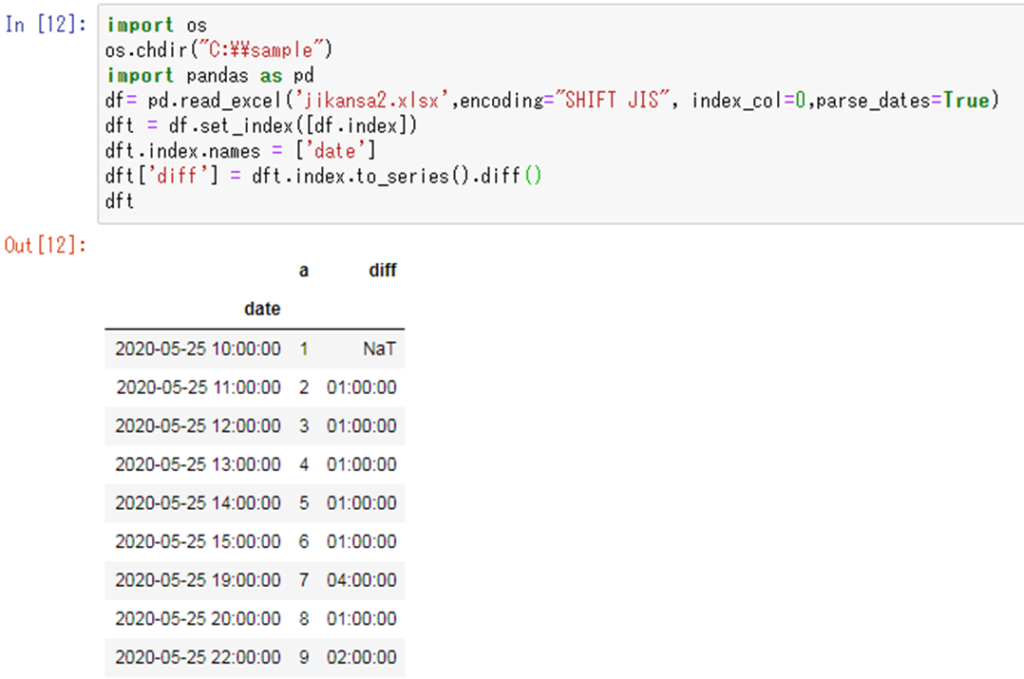
日でなく時間(hour)の差分も計算できる【diff】
なお、上では日付までの記載でしたがこれが時間(hour)までのデータであっても同じようにdiff()により時間の差分を求めることができます。


コメント