Jupyter notebook(Python3)を使ってみようと思っても慣れていないうちは、どうしても処理に躓いてしまうものです。
例えば、PythonのPandasライブラリを用いて曜日ごとの集計を行うにはどのように処理すればいいのか理解しています。
ここではこのpandasにて曜日ごとの集計を実施する方法や、曜日が数字で表す場合の曜日番号(pythonでは基本的に曜日は数値で表記)もまとめていきます。
Python(Pandas)にて曜日ごとの集計を行う方法
それでは以下のサンプルデータを用いてpythonにて曜日別の集計を行う方法について確認していきます。
集計といっても月ごとの合計、平均、標準偏差などいくつかの処理方法がありますが、基本的には
・データを曜日ごとにまとめる操作
・最後に処理したい集計方法の関数(平均など)の実行
の流れに従って対応するといいです。
以下のようなcsvを読み込み、曜日ごとの集計として今回は平均値を求めてみましょう。
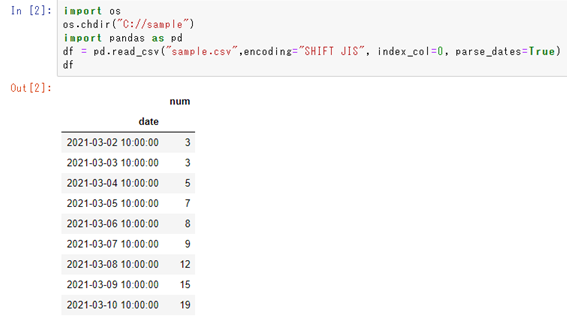
このデータを曜日ごとの集計していくには、以下のサンプルコードを用いるといいです。
os.chdir(“C://sample”)
import pandas as pd
df = pd.read_csv(“sample.csv”,encoding=”SHIFT JIS”, index_col=0, parse_dates=True)
df = df.set_index([df.index,df.index.weekday])
df.index.names = [“date”,”weekday”]
df.groupby(level=[“weekday”]).mean()
と処理すること曜日別の集計が完了します。
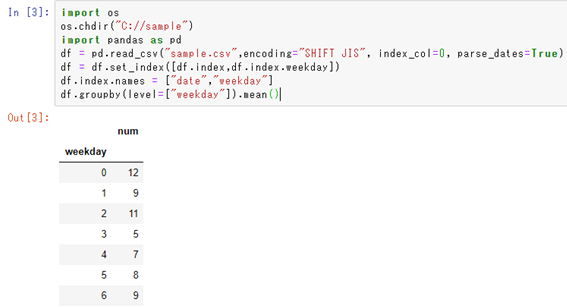
このコードの各々の意味は後ほど解説しているため参考にしてみてくださいね。
まずは上の出力結果の曜日の番号と実際に曜日(月曜日など)との対応を見ていきましょう。
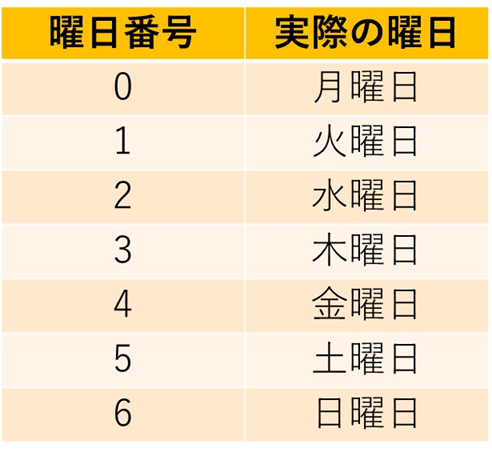
Pandasでの曜日番号の詳細(月曜日が0)
なお上のようにpython(pandas)にて曜日を表示する際には基本的に数値(番号)で表記されます。
曜日と数値の対応は以下の通りです。
・月曜日:0
・火曜日:1
・水曜日:2
・木曜日:3
・金曜日:4
・土曜日:5
・日曜日:6
月曜日から数字が始まり、かつその数値が0なことを覚えておきましょう。
曜日ごとの集計のコードの意味詳細
上に記載のコードの意味の詳細を解説していきます。
import os
os.chdir(“C://sample”)
→osライブラリのインポートし、csvが置いてあるディレクトリへ移動しています。
import pandas as pd
df = pd.read_csv(“sample.csv”,encoding=”SHIFT JIS”, index_col=0, parse_dates=True)
→pandasをインポートし、csvの読み込みしています。最後の, index_col=0, parse_dates=Trueにて0行目(最も左の日時データ)をインデックスとし、これを文字ではなく日時として読み込む処理をしています)。
df = df.set_index([df.index,df.index.weekday])
→これはマルチインデックス(インデックスが複数)にして処理しています。
日時データの場合、個人的にはマルチインデックスにした方が見やすいので、このように処理しています。インデックス1列目に日時すべて(df.indexの部分)、インデックス2列目に曜日(df.index.weekdayの部分)を表示させています。
df.index.names = [“date”,”weekday”]
→上のマルチインデックスの各列をdate(日時すべて)とweekday(曜日ごと)に変更しています。
df.mean(level=’weekday’)
→曜日ごとの集計(今回は平均(mean))を実行しています。
コードは1行ずつ丁寧にみていけば意味がわかってきますので、じっくり見るのが大事ですね。
特定の曜日のみの集計を行う方法【月曜日のみなど】
上ではすべての曜日のデータ集計を行っていますが、特定の曜日のみの集計を行いたい場合もあるでしょう。
以下で例として月曜日のみの集計を実施してみましょう。
以下のサンプルコードを使うといいです。
os.chdir(“C://sample”)
import pandas as pd
df = pd.read_csv(“sample.csv”,encoding=”SHIFT JIS”, index_col=0, parse_dates=True)
df.index.weekday
df[df.index.weekday == 0].mean()

ポイントは
df[df.index.weekday == 0].mean()
の部分で、インデックス列を曜日に変換し、続いて曜日が0(月曜日のみ)に該当するデータのみを集計し、平均を取っている形となります。
また特定の曜日だけの集計を行うにはマルチインデックスでは処理できないので、上のよう1つだけ(曜日)のインデックスとした上で対応するといいです。
まとめ Python(Pandas)のweekday機能を用い、月曜日などの曜日ごとの集計を行う方法
ここでは、Python(Pandas)にて曜日ごとの集計を行う方法について解説しました。
・日時データとしてインデクスを読み込み
・曜日に変換
・曜日別のスライスを行い集計
にて処理するのがのがポイントですね。
Pandas(Python)での各種処理方法に慣れ、より効率的なデータ解析を行っていきましょう。

コメント