Pythonのpandasは時系列データの処理等を行う際に非常に便利なツールといえます。
ただ、pandasの使用方法に慣れていないとなかなかうまく処理できないケースも多いです。
中でもここでは、pandasにて指定の列をインデックス(index)列にする方法について解説していきます。
Python(Pandas)にて指定の列をインデックス(index)にする方法
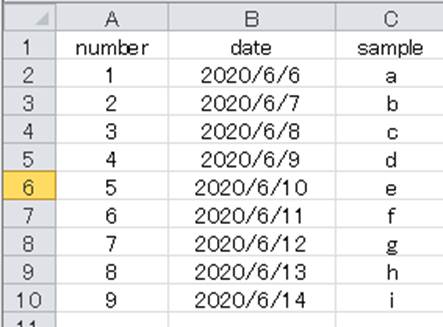
以下のようなexcelデータを扱い、pandasのデータフレームにて指定の列をインデックス列にする方法について解説していきます。
今回はこの中でもdateの列をインデックス(index)に指定したいとしましょう。
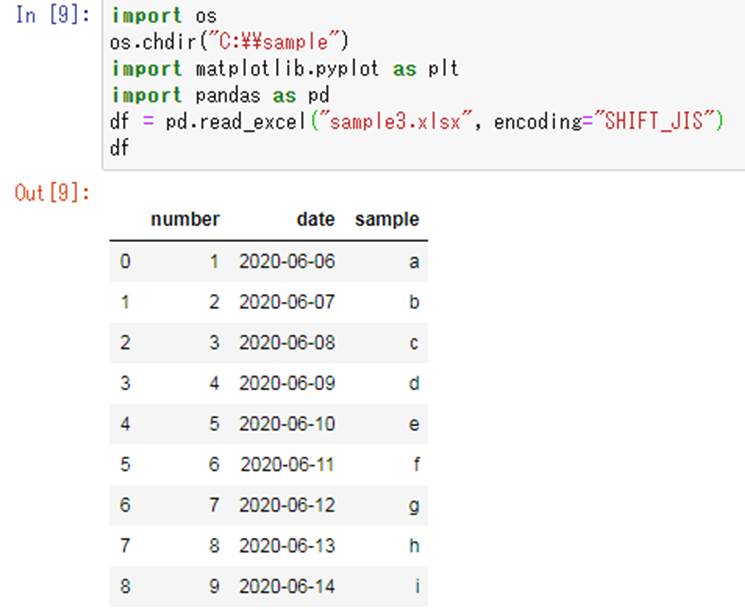
単純にpandasにてexcelファイルを読み込むだけではインデックス列が指定されずに、自動で数値が降られます。サンプルコードは以下の通りです。
os.chdir(“C:\\sample”)
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel(“sample3.xlsx”, encoding=”SHIFT_JIS”)
df
この出力結果は以下の通りとなります。
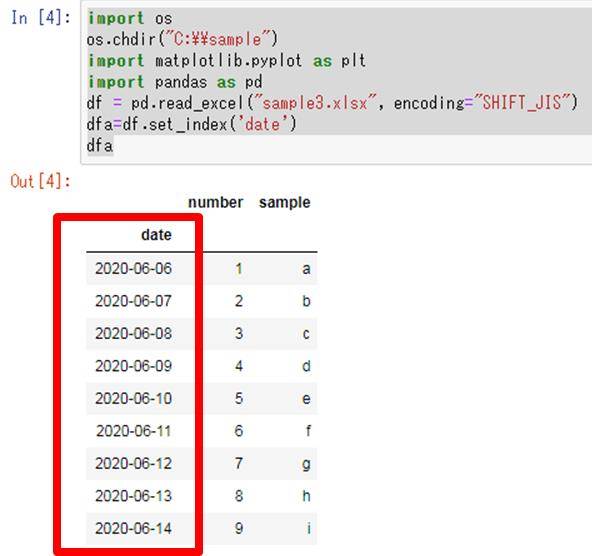
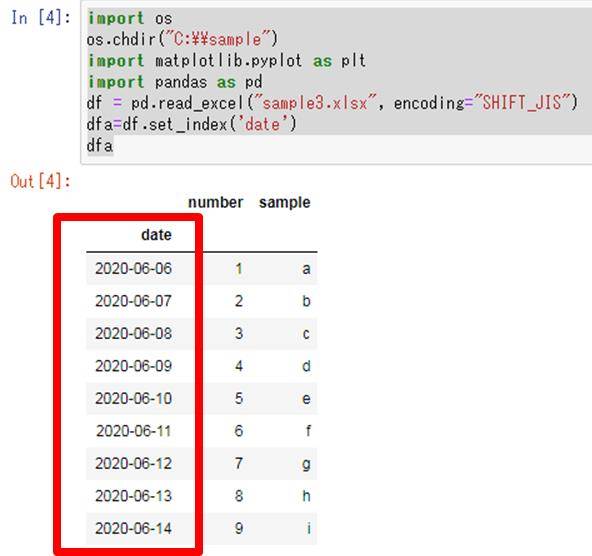
この中の指定の列(date)をインデックスにする場合には、df.set_index(‘列名’)とすればいいです。
すべてを併せたサンプルコードは以下の通りです。
os.chdir(“C:\\sample”)
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel(“sample3.xlsx”, encoding=”SHIFT_JIS”)
dfa=df.set_index(‘date’)
dfa
これによって、pyhon(pandas)にて指定列をインデックス(index)に振り直すことができるのです。
【列番号で指定】Pandasにて予めインデックスの列を指定をしてexcel,csvを読み込む方法
なお、df.set_index()を用いてインデックスの指定を行う方法を確認しましたが、excel,csvを読み込む段階で列番号を指定することでも対処できます。
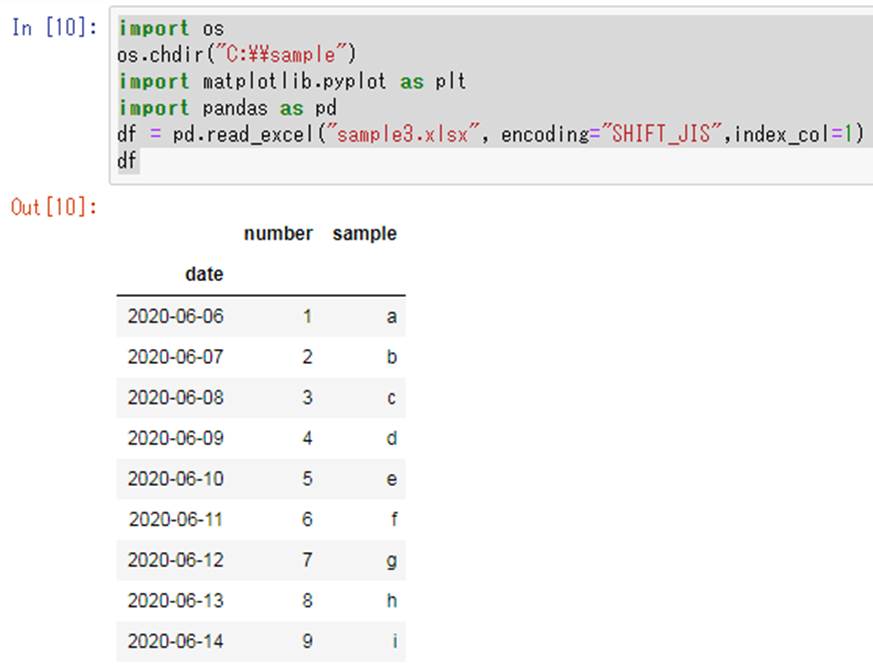
今回はdateの列番号が1なので(一番左が0)以下のindex_colの中の数値に1を指定しています。
os.chdir(“C:\\sample”)
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel(“sample3.xlsx”, encoding=”SHIFT_JIS”,index_col=1)
df
すると以下のように結果が出力されるのです。
まとめ Python(pandas)にて指定の列をインデックス(index)列にする方法
ここでは、Python(pandas)にて指定の列をインデックス(index)列にする方法について解説しました。
Pythonの扱いは慣れればなれるほど上達するので、さまざまなパターンに触れていくといいです。
Pythonのスキルを上達させ、毎日の業務を効率化させていきましょう。


コメント