
Jupyter notebook(Python3)を使ってみようを使ってみようと思っても慣れていないうちは、どうしても処理に躓いてしまうものです。
例えば、pandasにて基本的な統計量である標準偏差を求めるにはどのように処理するといいのか理解していますか。
ここでは、jupyternotebookにおけるPandas機能を用いて列や行ごとの標準偏差を計算する方法について確認していきます。
Pandasにて標準偏差(列や行ごと)を計算する方法【pythonにおけるstd関数の活用】
まずは以下のようなcsvデータをpandasにて読み込み、データフレームに取り込んでみます。
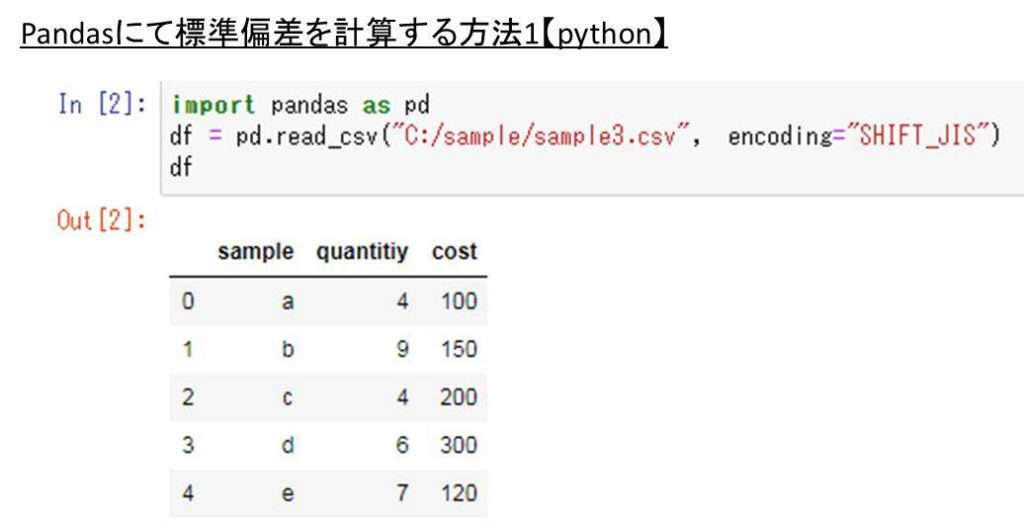
ここで、pythonにて列ごとの標準偏差を計算するためには、std関数を使用するといいです。
サンプルコードは以下の通りです。
import pandas as pd
df = pd.read_csv(“C:/sample/sample3.csv”, encoding=”SHIFT_JIS”)
df.std()
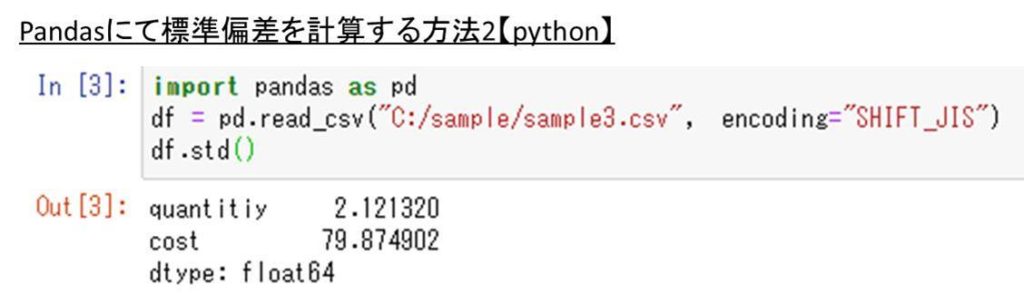
これだけで、列ごとの標準偏差がpythonにて計算されました。
なお、数値でなく英語や記号の列は標準偏差が出力されないことも理解しておくといいです。
Pandasにて特定の列のを標準偏差を求める方法【列指定などの範囲や条件の指定】
さらには、すべての列を標準偏差を計算するではなく、列指定を行って一部の列のみの方順偏差を求めていきましょう。
特定の1列のみの場合は、dfの後に直接列指定したい列のヘッダー名を記載して、std関数で処理するといいです。
import pandas as pd
df = pd.read_csv(“C:/sample/sample3.csv”, encoding=”SHIFT_JIS”)
df[“cost”].sum()
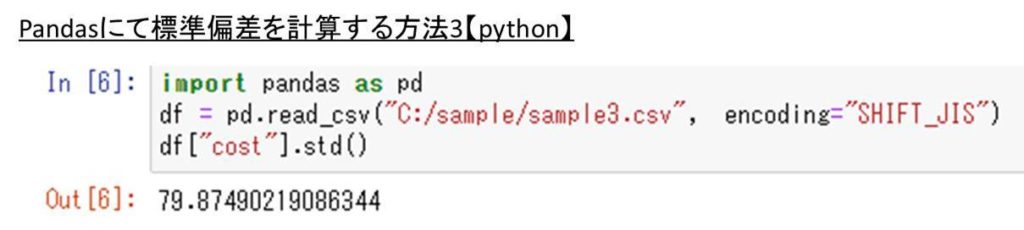
Pandasにて特定の複数列の標準偏差を計算する方法【std関数】
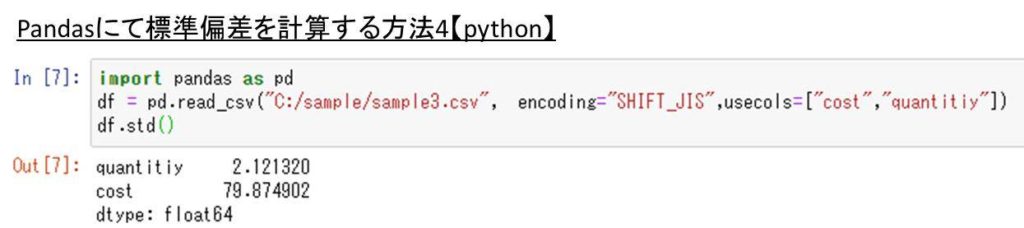
なお、複数列を指定した上での標準偏差を求めるには、csvなどを読み込む際に予めその列を指定、データフレームに取り込んだ上で計算するといいです。
import pandas as pd
df = pd.read_csv(“C:/sample/sample3.csv”, encoding=”SHIFT_JIS”,usecols=[“quantitiy”,”cost”])
df.std()
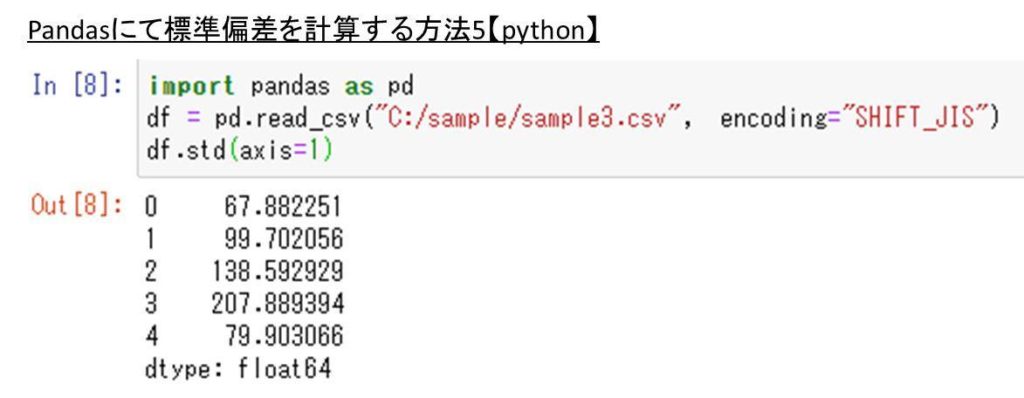
Pandasにて行方向(横方向)の標準偏差を計算する方法【pythonにおけるdataframe(データフレーム)】
今度はpnadasにて列方向ではなく行方向の標準偏差の計算も行っていきましょう。
行方向を指定するにはコード中にaxis=1をいれるといいです。
import pandas as pd
df = pd.read_csv(“C:/sample/sample3.csv”, encoding=”SHIFT_JIS”)
df.std(axis=1)
まとめ Pandasでの標準偏差の計算方法【列や行ごと(python)】
ここではpythonのpandas機能において、列や行のごとの標準偏差を求める方法について解説しました。
基本的にはstd関数を使用するとよく、適宜特定の列を指定したり、行方向に切り替えたりと処理するコードを足していくといいです。
各種対処方法を理解して、pythonにおけるpandas機能の使い方をマスターしていきましょう。


コメント